Why would you fight with Rails to use a different architecture style? This was the question I first asked myself when considering how to structure this project. As anyone with a passing familiarity with Rails can tell you, its strong point is the trusty axiom of convention over configuration. You start a new project, everything gets scaffolded out for you exactly where it needs to be for Rails to do its magic, and boom, you’re already working on the meat and potatoes of the application. So why mess with that?
Well, different teams and projects will have different answers to this question, but for me it was mainly a matter of curiosity and an interest in trying a different sort of architecture. I had read about DDD and clean architecture and wanted to try and apply it to learn more effectively. (For instance: Patterns, Principles, and Practices of Domain-Driven Design by Scott Millett, Architecture Patterns with Python by Harry Percival and Bob Gregory, or Clean Architecture by Robert Martin.) I could have stuck with plain Ruby or used C#, which seems to be popular among DDD practitioners. (This is probably because DDD/clean architecture only really shines in large, complicated projects which are more likely to exist in large organizations using enterprise-y languages.) Or I could have used any number of other languages or frameworks. But, I’d already spent plenty of time writing C# and was looking to deepen my knowledge of Ruby and Rails. I decided to try this experiment to see how hard it is to change parts of the typical Rails project structure, which would force me to learn more about Rails internals.

Even though it’s not recommended to use this style of architecture for simpler projects, I did find it ideal to be able to focus on what needed to be done to reorganize the project, and how to work around Rails and Rails-integrated libraries like Devise, without getting too wound up in the finer details of a complex project’s business rules, strictly for learning purposes. Right now this job board site is pretty simple, without a lot of business rules. So in the “real world”, it wouldn’t be a great candidate for DDD/clean architecture - it would have been perfectly suited to the standard Rails MVC architecture. But aside from the desire to simply experiment as I mentioned before, I also reasoned that this project could grow more sophisticated and become a site I maintain for the long term. If that scenario materializes, then I’ll be glad for having already built a solid foundation to extend the app easily.
I did end up spending a fair amount of time looking at the Rails/Devise source code to try to understand what was going on, particularly when working on separating my domain entities from the ActiveRecord functionality, while still retaining a lot of the nice features you get from using ActiveModel for use in templates (views in Rails terminology). There were certainly some afternoons of head-scratching which I’ll detail later, but otherwise, I found that Rails is still flexible enough to let you do what you want after a bit of wrestling. So, with all that being said, I’ll move on to the guts of what changes I made.
What had to be changed to support clean architecture?
As you would expect, most of the changes to the project structure are within the app folder. Instead of sticking with the standard controllers/models/helpers/views folders, I had to add some extra folders and rearrange things a bit. I made some of these changes in separate stages over time, as I was continuing to read about architecture and decided to make some changes I had written off as too complicated before.
Here’s the overall project structure:
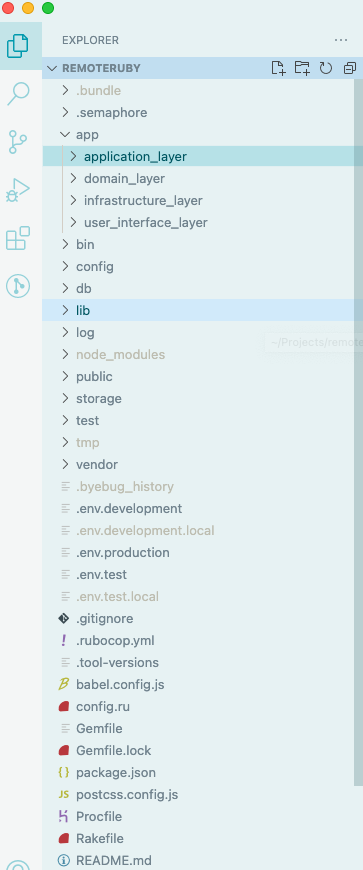
There are now application, domain, infrastructure, and presentation layer folders in their place. These can somewhat be equated with the MVC pattern that Rails starts you with as a starting point to understand the differences, but of course this isn’t an accurate comparison once you get beyond scratching the surface. Explaining clean architecture concepts fully is well beyond the scope of this post, so again I would point to the resources mentioned earlier if you want to get a better understanding first. To help myself visualize everything going on in the app, I created this graphic showing the layers, what exists in those layers, and the relationships between them. It is a lot to take in, so I’ll include parts of the graphic focusing on the individual layers when discussing each one specifically. Click here to view the diagram in detail.

Domain Layer
Moving on to cover each of these main layers of architecture, I’ll start with the domain layer. This is where the typical ActiveRecord models would be in a standard Rails project, but here they are our DDD business domain entities. Focusing in on the diagram from before, you can see this is a fairly thin layer(click here to view the diagram in detail):

And here’s the folder structure:
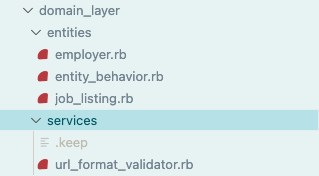
Domain services are also here and provide any business logic that isn’t directly tied to a single domain entity. For example, a URL format validator. The domain entities themselves contain business logic such as enforcing invariants through validation. For example checking that a JobListing includes either a contact email or valid URL to apply to, or that the min salary range is less than the max.
I did have to do a workaround for Devise integration since it expects validations to exist on the ActiveRecord model itself. So I put the Employer validations into a module that could also be included on the EmployerRecord. Even though this is a hack around the strict layered dependency architecture, it was a necessary evil to work with an external library that was tightly coupled to ActiveRecord. Software engineering requires making tradeoffs where necessary when you are dealing with real world constraints. At least here the hack is contained to a single module and clearly named and documented as to its purpose and why the workaround was necessary.
# Define validations in a re-usable module so that we
# can also apply it to the ActiveRecord EmployerRecord
# since Devise is so tightly coupled to it.
# Then the devise controllers will work out of the box
# with the validations
module DatabaseValidations
def self.included(klass)
klass.instance_eval do
validates :name, presence: true
validates :email, presence: true
end
end
end
include DatabaseValidations
One last aspect of the domain entities worth mentioning in this project was separating the readable and writable attributes at the domain entity level. Doing this guarantees I won’t accidentally try to overwrite the created_at or updated_at timestamps or provide access to attributes that the UI layer doesn’t care about. For example, ResultEntities should only ever be set up with getters for the getter attributes defined on the entity, plus the errors attribute to help display which fields have errors on forms. These result entities are modules that are basically a bag of attributes like a struct, except they include some ActiveRecord::Model behavior to play nicely with Rails link and form helpers.
Application Layer
This layer coordinates all of the high level ways a user would interact with your app, otherwise known as “use cases”. I broke this layer down further into commands and queries, following the CQRS (Command Query Responsibility Separation) pattern. The command/query separation was one change I added much later on. Since I already had a nice neat repository and set of use cases, it was as simple as splitting the repository methods and use cases that update/create data into the commands folder, and likewise, the methods and use cases that only query for data to be displayed got moved into the queries folders. The only downside I think this had was not being able to clearly see one simple folder called “use cases” and immediately check there to get a high-level sense of what all the app does anymore. It’s not much more complicated or opaque now in my opinion, but take a look for yourself:
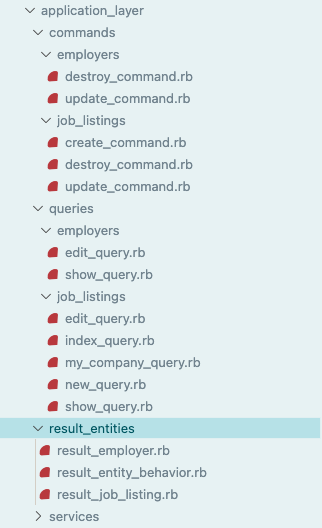
And here’s a closer look at the diagram from before, just focusing on this layer and what connects to it from outer layers (click here to view the diagram in detail):

Within the command/query folders, use cases are further broken out by domain entity to avoid name conflicts. Each use case has a call method that returns a Result struct that the calling controller can then pass on to its respective view model to produce a template. As for the call method itself, the calling controller must provide the repository to use through dependency injection. The command or query then uses that repository to perform database operations. In some of the commands I had to pass in both the command and query repositories when they needed to fetch an entity, run business logic on it, then update it in the database after.
One other point on the commands is that I opted to put some very basic sanitizing methods here rather than in the repository, the domain layer, or even in JS. For example converting “$80,000” to “80000” before passing it into the domain layer. The controller definitely isn’t the right spot since its only responsibility is to call use cases with data from user input and pass the result of use cases along to view models - adding sanitizing methods there would muddy up that single responsibility. I could very well have put the sanitizing code in the front end, especially for the salary/compensation fields, but that wouldn’t work for users with JavaScript disabled.
The last component of the application layer is the result entities. These are objects that correspond to domain entities. They get packaged up into the result struct which is returned from use cases to the controller. This was one of the main parts that involved head-scratching and a lot of looking at Rails documentation. I wanted the result entities to be simple objects, but still play nicely with Rails link and form helpers. This took a bit of trial and error to figure out what specific ActiveRecord modules needed to be included (to_param, to_key, persisted?, etc.).
# Takes a domain entity's attributes
# and gives it ActiveModel-aware behavior
# for Rails helpers like form_for
module ResultEntityBehavior
def self.included(klass)
klass.instance_eval do
# Act like an ActiveRecord model
include ActiveModel::Model
# Work with Rails path helpers
include ActiveModel::Conversion
Including ActiveModel::Model and ActiveModel::Conversion provided most of the functionality Rails expected. Then I just had to define a few methods like attributes, [], persisted?, and model_name. Some of those methods needed to be prepended to the model so that they would be found first in the list of ancestor modules to override the defaults provided by including ActiveModel::Model, such as the default implementation of persisted? in ActiveModel::API which just returns false. I also had to override model_name because I’m using JobListingRecord as the actual ActiveRecord object rather than just JobListing, which is the domain entity and kept separate from Rails as much as possible.
module InstanceMethods
def model_name
ActiveModel::Name.new(self.class::ENTITY_CLASS)
end
def attributes
attributes = {}
self.class::ENTITY_CLASS::ATTRIBUTES.each do |attribute|
attributes[attribute] = public_send(attribute)
end
attributes
end
def [](key)
attributes[key.intern]
end
def persisted?
id.present?
end
def valid?
errors.empty?
end
end
So ultimately, the ResultEntity classes correspond to the actual domain entities, but are meant for consumption by higher level layers and only include read-only attributes, without any of the business logic methods you would find at the domain layer.
Infrastructure Layer
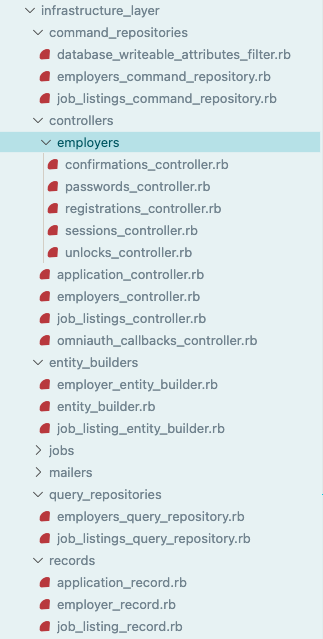
At this layer, we have our standard Rails-style controllers that just get what they need from the corresponding use case, then build the view model (some people call these presenters) to make things ready for the template. The repository modules are in this layer as well: these do the job of interacting with the database through ActiveRecord. This is the only place in the code that interacts with the database, meaning that everything else that wants to query or update data has to go through the repositories. And the only code that should be using repositories is in the application layer in the form of commands/queries. The repository returns domain entities instead of ActiveRecord models like you’d see in typical Rails applications. ActiveRecord such as EmployerRecord and JobListingRecord are in the record folder at the infrastructure layer. As a reminder these are ActiveRecord objects rather than domain entities. Their only purpose is to provide database access to the repositories through the ORM.

(Click here to view the diagram in detail.)
The records override #table_name so that ActiveRecord can map to the proper table names instead of the default behavior of Rails where it assumes the DB table is the same as the model name.
class EmployerRecord < ApplicationRecord
self.table_name = "employers"
# more stuff here...
class JobListingRecord < ApplicationRecord
self.table_name = "job_listings"
# more stuff here...
This code tells AR to map to the job_listings and employers tables instead of the default of job_listing_records and employer_records.
The last component of this layer is entity builders that translate ActiveRecord objects to regular domain entities with only the specified readable attributes populated. They’re returned by repositories to the application layer where their validation and other business logic can be used. Other infrastructure concerns like mailers and jobs belong in this layer too. They would be passed into commands/queries at the application layer through dependency injection, so that the application layer provides an interface through its calling convention, and the infrastructure layer implements that interface. Thus keeping the direction of dependencies one way always facing one closer to the center of the architecture.
For example, here we pass the appropriate repository to a use case in order to show an individual employer’s profile:
def show
result = Employers::ShowQuery.call(
employers_command_repository: EmployersCommandRepository,
id: params.fetch(:id),
)
# more code setting up the view model...
Most of the other use cases are very similar.
User Interface Layer
Last but not least we have the user interface (presentation) layer. All the static resources, JS, CSS, and templates (_.html.erb, _.js.erb) are here of course.
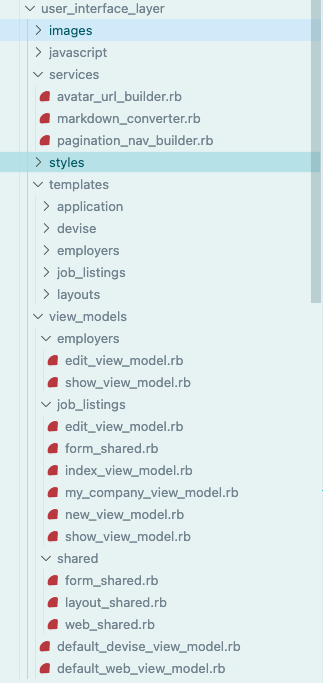
It’s important to note that what the Rails world would call “views”, I opted to call templates (like Phoenix does) in keeping with a more framework-agnostic terminology - otherwise these are just standard erb views. The view models folder in this layer gives presentation logic to the templates without cluttering up the actual templates with logic.
module JobListings
class IndexViewModel
include Shared::WebShared
attr_reader :job_listings, :search_text, :sort_column
private
attr_reader :paginator, :request, :filtering_by_employer
def initialize(current_employer:,
job_listings:,
paginator:,
search_text:,
filtering_by_employer:,
sort_column:,
request:,
)
@current_employer = current_employer
@job_listings = job_listings
@paginator = paginator
@search_text = search_text
@filtering_by_employer = filtering_by_employer
@sort_column = sort_column
@request = request
end
public
def job_listings?
job_listings.any?
end
# more methods here...
For example, handlers for form groups and errors, and bits of logic that determine whether to show or hide certain fields, or what text to display on buttons. Reusable logic that doesn’t belong to any one view model in particular also exist here as UI services. There isn’t really anything else out of the ordinary going on in this layer - after all, it’s the outermost layer, so it makes sense it should be the least impacted by the changes made to segregate Rails from the domain.

(Click here to view the diagram in detail.)
So at this point, I’ve covered most of the differences in the project structure at the layer level and the quirks involved in that. There’s a couple final modifications worth mentioning that happened outside the layers that I haven’t covered yet, though. One of the most important spots to work with at this level is the application.rb file. This tells Rails where to find modules that are an extra layer deep in our folder hierarchy within app, without requiring an extra module for each layer.
####################
# Domain Layer
####################
# Domain entities. Note that top-level entities are aggregates
config.autoload_paths << Rails.root.join("app/domain_layer/entities")
config.autoload_paths << Rails.root.join("app/domain_layer/services")
####################
# Application Layer
####################
# A single point of interaction with the application layer
config.autoload_paths << Rails.root.join("app/application_layer/queries")
config.autoload_paths << Rails.root.join("app/application_layer/commands")
config.autoload_paths << Rails.root.join("app/application_layer/result_entities")
# etc...
Finally, there’s routes.rb, where I needed to specify a custom class name for Devise to map to the ActiveRecord class rather than the domain entity.
Rails.application.routes.draw do
# Authentication
devise_for :employers,
class_name: "EmployerRecord",
controllers: {
# etc...
That covers it! I hope this was informative for anyone interested in the intersection of Rails and DDD/clean architecture. Drop me a line if you have any thoughts on it!